Menu
Archipelago Data Ingestion
Role
Lead Product Designer
Description
Our design team built the scaling of Archipelago's complex data ingestion tooling while optimizing for complex behavioral problems.
Background
Archipelago specializes in taking complex datasets for commercial properties and making them manageable, succinct, and agreed upon by the industry. One of our key capabilities is attaching evidence to where the data originated from. 'Ingesting' this data onto our platform requires a specialized expertise, and a dedicated team to do it. The legacy experience for this team was cumbersome, error-prone, and costly. Our task, and KPI, was to make this manageable for a non-technical team to do at higher efficiency.

Research
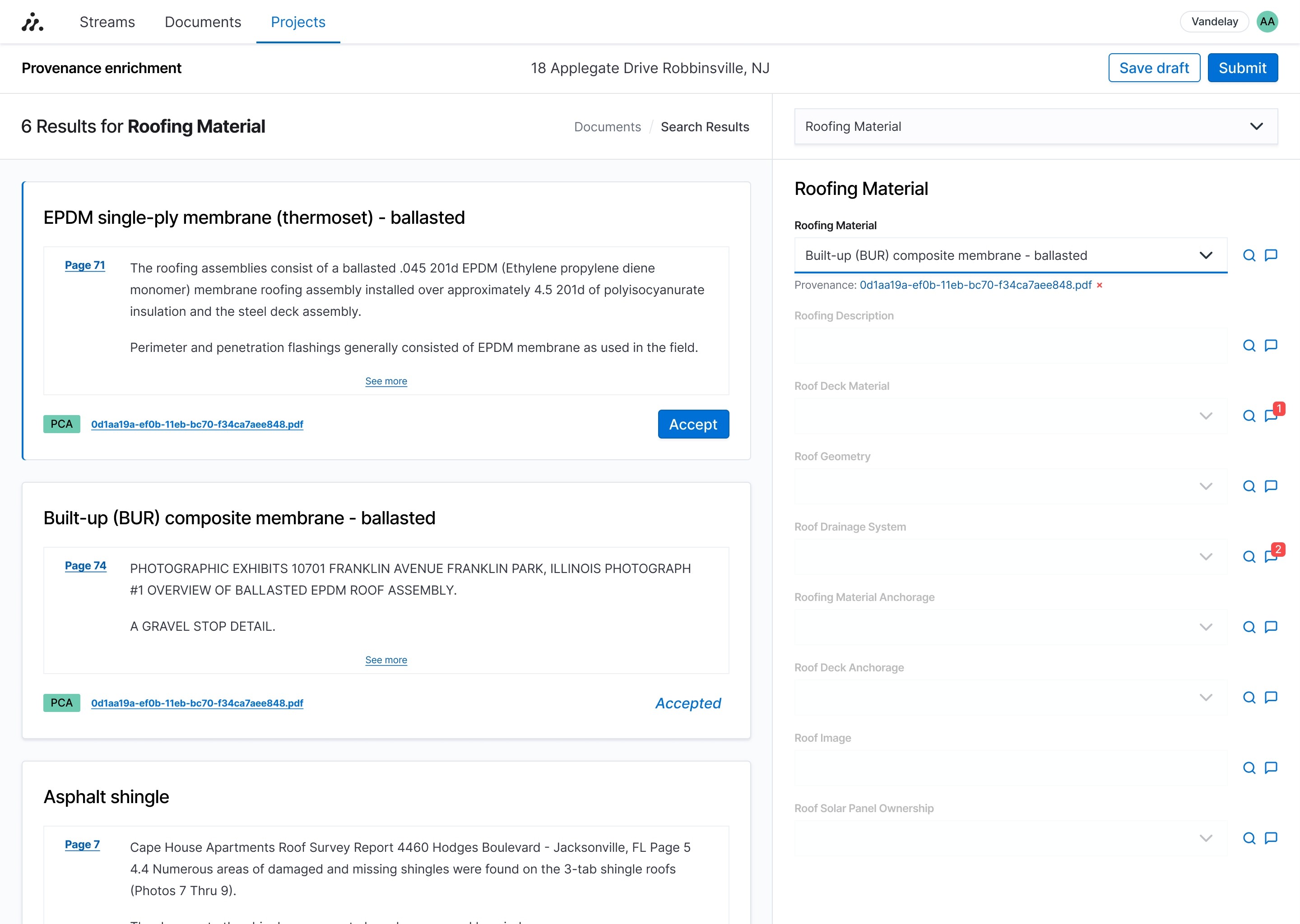
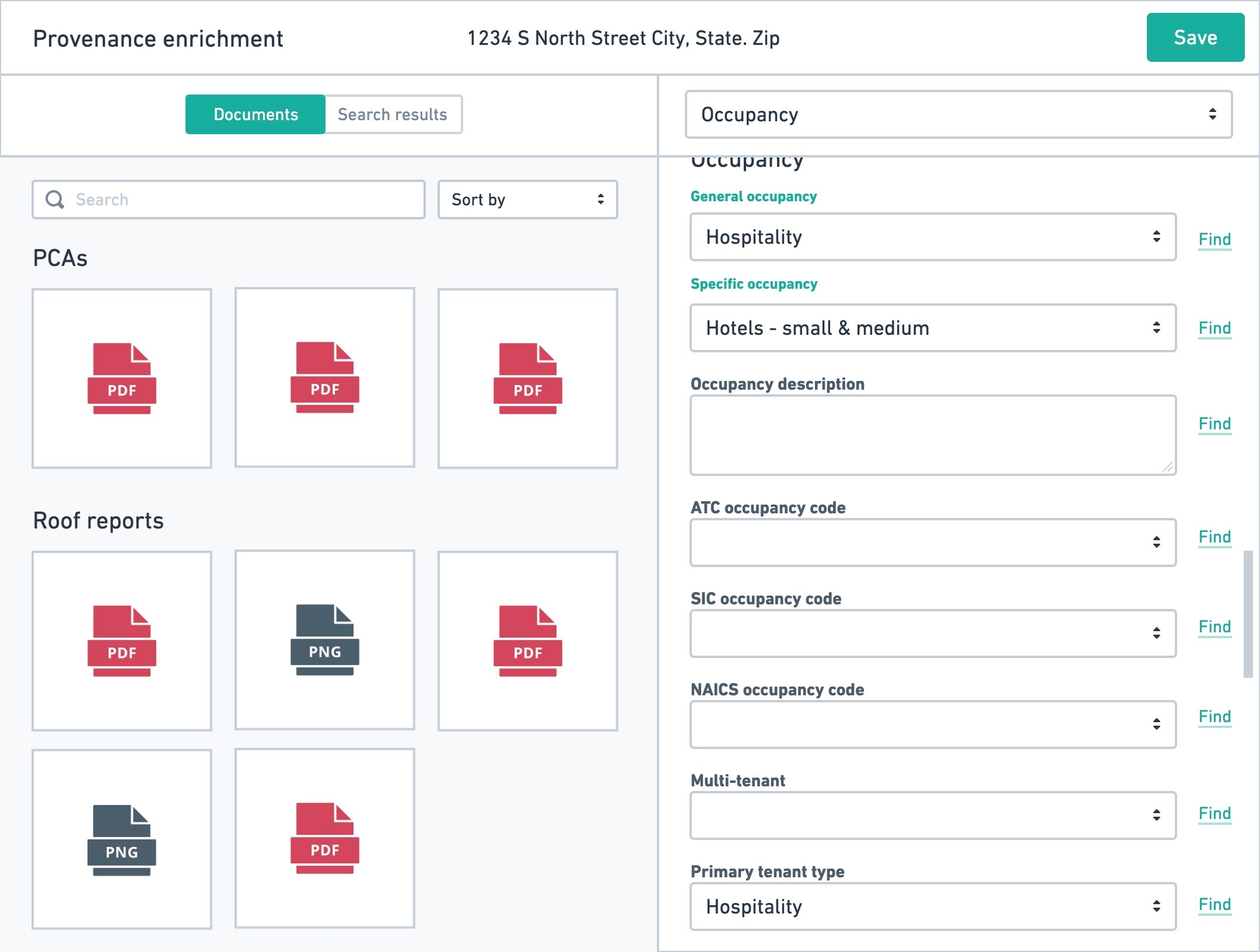
To best understand how data workers did their work, we conducted a number of interviews, participated in working sessions, and utilized their existing spreadsheets (see above) to understand how they performed their jobs. One of the key problematic areas was the inability to work on multiple properties at once as well as having to manage the downloading and uploading of Excel spreadsheets to the platform — causing friction and representing a major bottleneck in the efficiency of their work.
Design
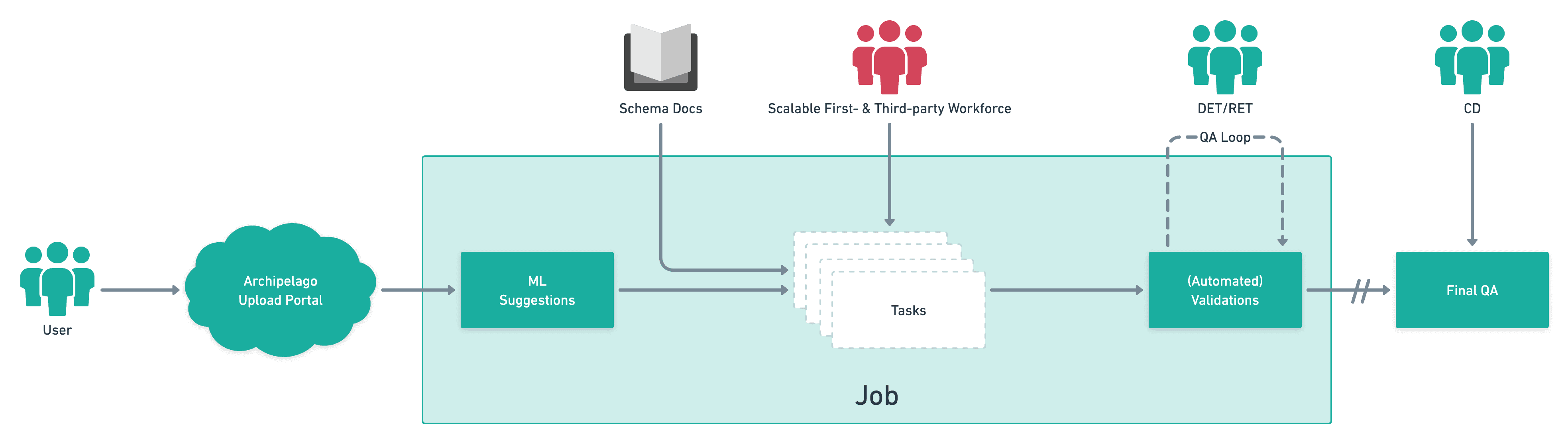
After the scope of the problems had been properly defined, our KPIs set, we began workshopping ideas on how our data workers could do their jobs on the platform, as opposed to in Excel, thus unlocking the ability create a tightened UI for their tasks, utilizing data validations to check their work, and give us more insight into their work capacity, and so on.
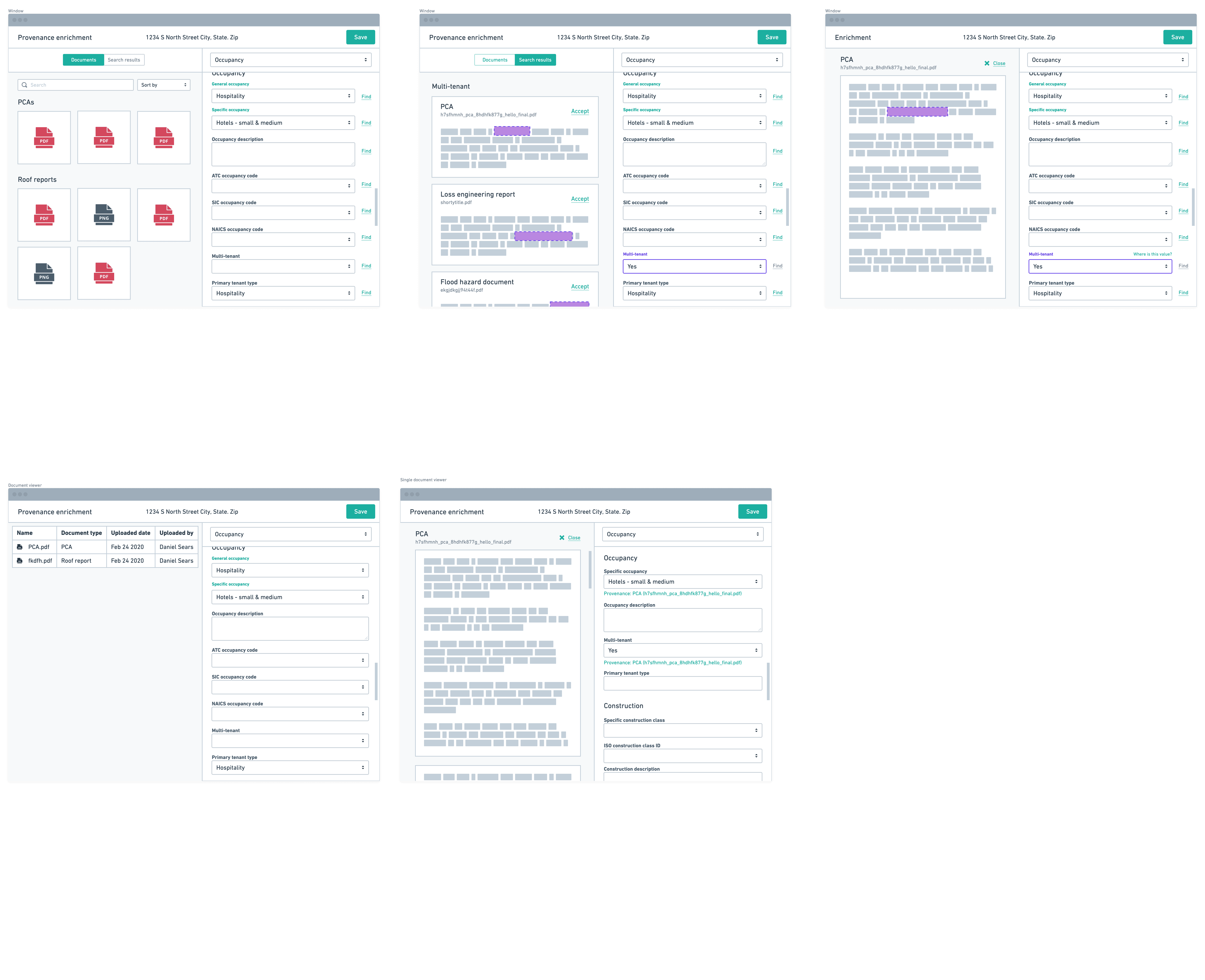
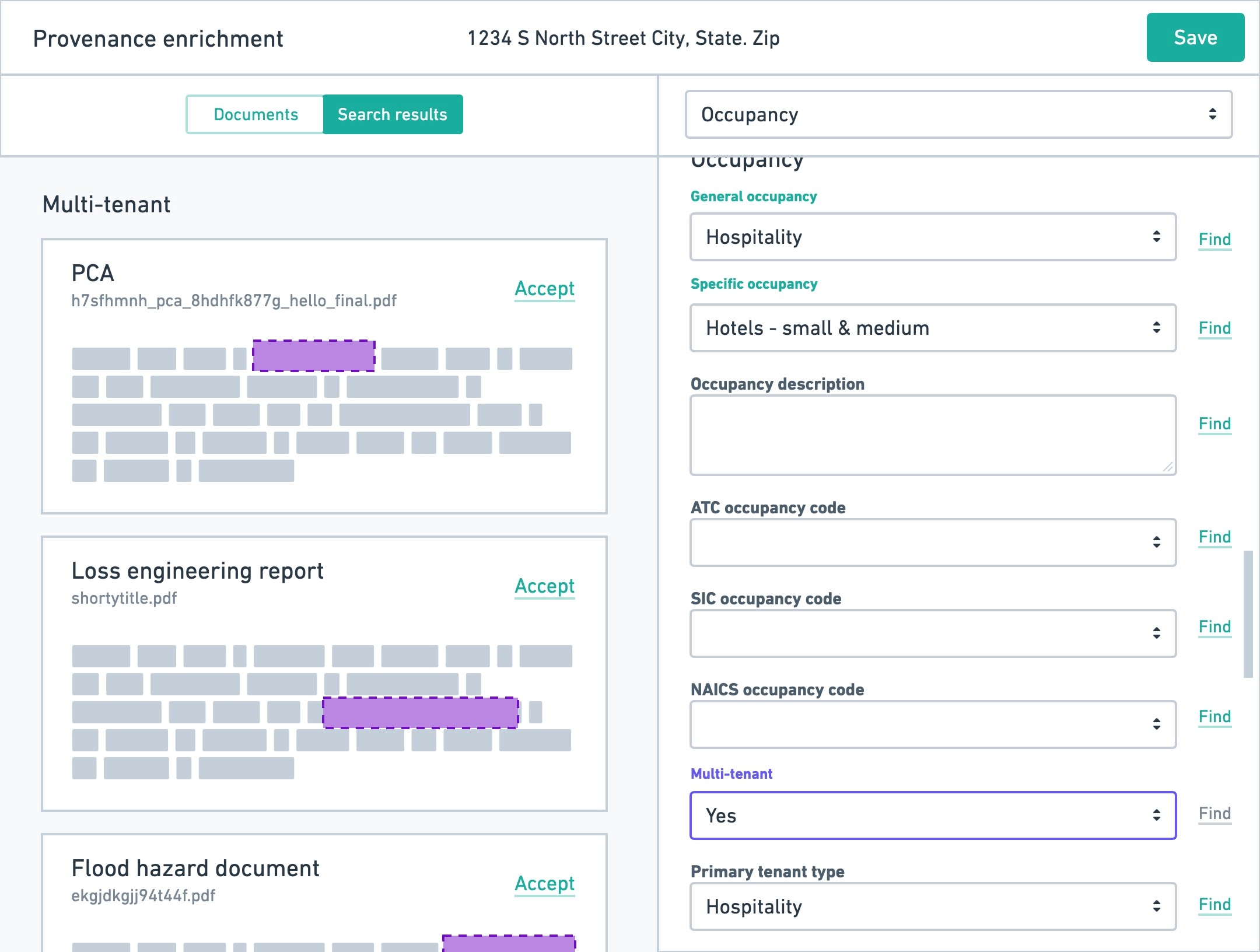
We eventually settled on the idea of having a split view where workers could work on the PDFs they had to review while also giving them the ability to edit data on the platform. Initial prototypes supported the idea that this concept could be scalable for when data workers needed to do work on multiple properties at once.
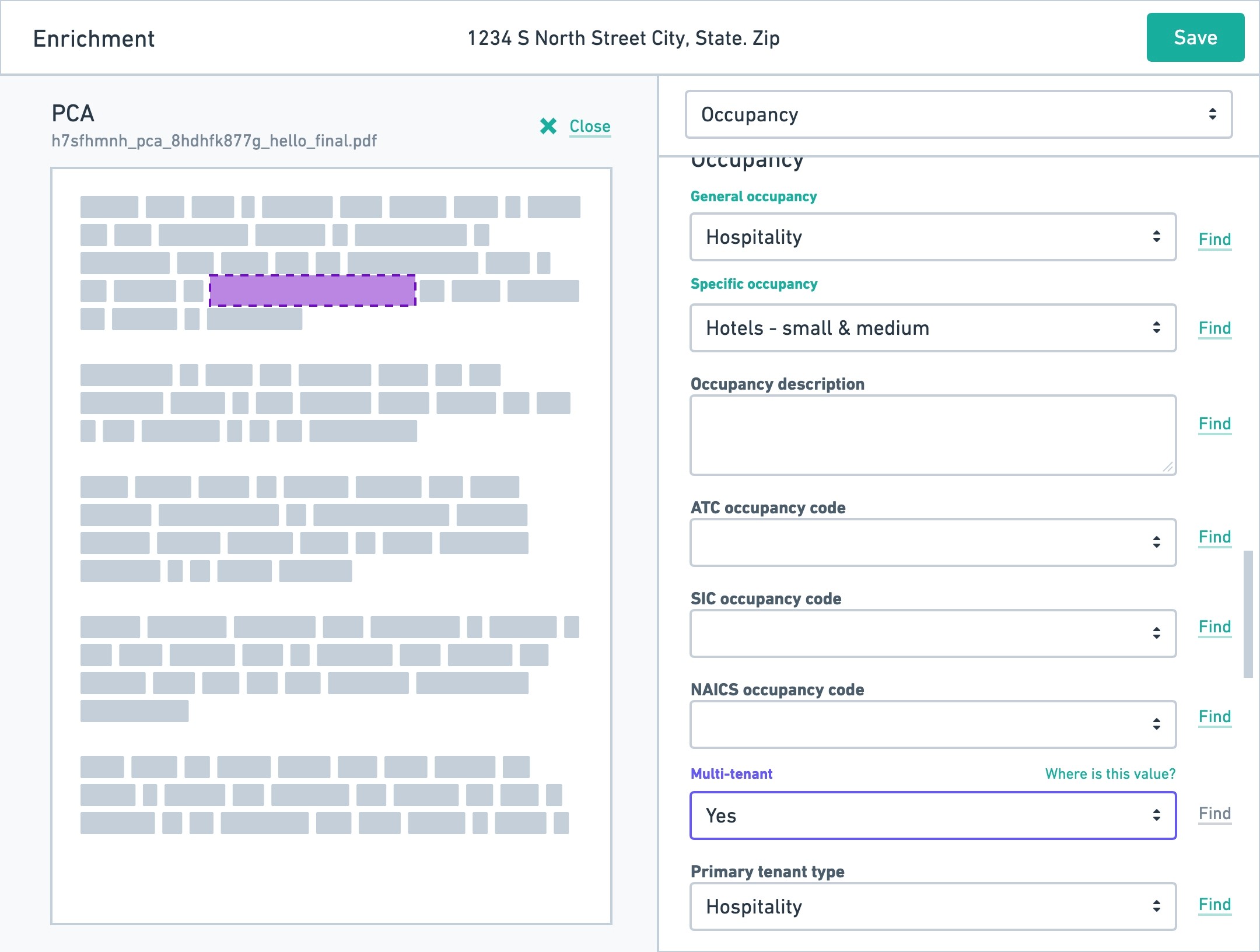
When the data workers performed their work, and enriched the property data (a term we use to describe improving a customer's data), the platform would automatically assign the evidence of the work they did based on the PDF they were working from. This both created an audit trail internally for what work was done, but also exposed this important piece of information to our customers that rely on this for their portfolio to be trustworthy.
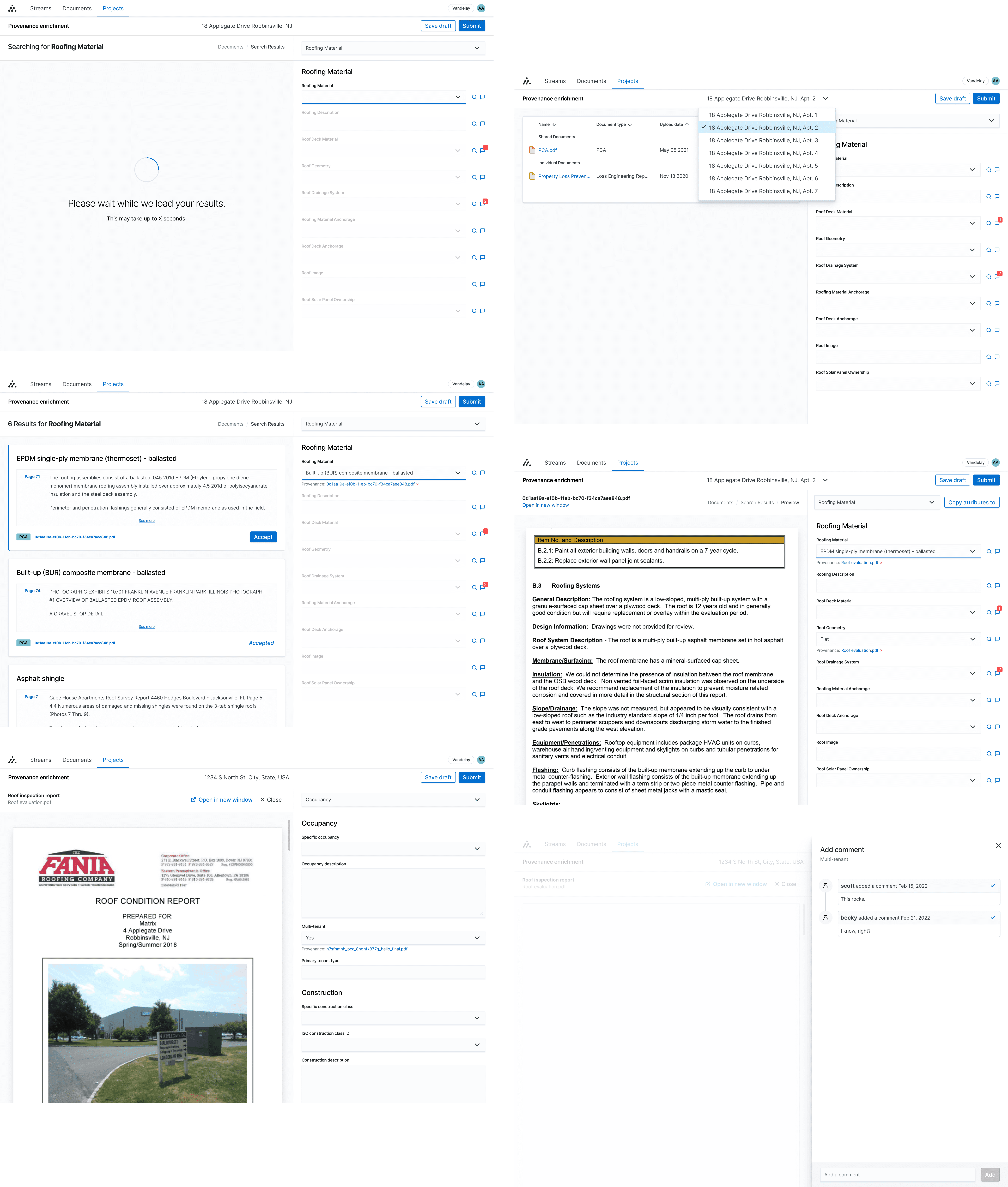

Testing, results, and beyond
To ensure that our improvements were exceeding our expectations, we ran a series of user tests on our data workers to make sure they properly understood its functionality, hit specific touch points, and increased their time for data input.
Once the functionality had been built, our initial measurements showed a decrease in median job duration of 57% (down from 37 minutes to 16 minutes per job). Given the often large data sets, this represented a massive improvement in efficiency and helped improve our company goal to deliver on scaling larger data ingestion projects.
The project continues to grow with improvement and enhancements including a commenting system, multiple properties per job, machine learning document searching, and more.